ML Estimation for a Discrete Linear Observation Model#
In this section, it is assumed that the parameters \( \alpha_l, l = 1, \dots, L \), are to be estimated from the received samples \( y_i, i = 1, \dots, k \), by forming the weighted linear combination given by
where \( h_{il}, i = 1, \dots, k \) and \( l = 1, \dots, L \), are real coefficients and \( n_i \) are samples of zero-mean Gaussian noise.
The noise is, in general, nonwhite with a covariance matrix \( R_n = \mathbb{E}[\vec{n}\vec{n}^T] \), where \( \vec{n} = [n_1, \dots, n_k]^T \).
In matrix notation, Eq. (12.1) can be expressed as
where
In this formulation, the matrix \( H \) is referred to as the channel matrix.
This representation is a generalized version of the amplitude estimation problem treated in Section 11.4, although as Example 12.1 indicates, it has a much larger application.
Example#
This simple navigation example [B2, Ex. 12.1] indicates the practicality of the above signal model.
Assume that a navigation system exists with four reference stations located at known Cartesian coordinates \( X_i, Y_i, Z_i \), \( i = 1, \dots, 4 \).
These stations are synchronized in time, and each one transmits a navigation signal at a known time \( t_i \), \( i = 1, \dots, 4 \).
A vehicle has an initial estimate of its location at \( X_0, Y_0, Z_0 \); however, its actual location is at \( X_0 + \Delta x, Y_0 + \Delta y, Z_0 + \Delta z \).
Furthermore, it has a clock error of \( \Delta t \). Thus, the vehicle’s measurement of arrival time of the navigation signal from reference \( i \) is
where \( c \) is the speed of light.
If we expand this equation in a Taylor series around \( \Delta x = 0, \Delta y = 0, \Delta z = 0 \), and if we let
then
where we have kept just the linear terms in the Taylor series.
Subtracting the known constants \( d_i / c \) and \( t_i \) from both sides of this equation, we arrive at a new measurement, which can be interpreted as an error-measurement term:
Generalizing to all four error-measurement terms (\(i = 1, 2, 3, 4\)), we can write
where
and
This example is a much-simplified form of the navigation approach used by the Global Positioning System (GPS) satellite navigation system.
In the GPS system, the reference stations are orbiting satellites; because the satellites are moving and the vehicles are potentially moving, the GPS system also solves for velocity terms as well as position terms.
In addition, the GPS solutions use a circular coordinate system rather than the Cartesian coordinate system of this example.
Finally, most GPS receivers use forms of the Kalman filter rather than the linear estimation procedure of this example.
ML Estimation#
Returning now to the general theory, we seek an ML estimate from the conditional pdf \( p(\vec{y}|\vec{\alpha}) \) given by
The derivative of the log-likelihood is computed from
or in vector notation
To continue the evaluation of this equation, the following matrix identities are needed:
where
\( P \) is an arbitrary \( k \times k \) element matrix
\( \vec{w} \) and \( \vec{v} \) are \( k \)-element real column vectors.
With these identities, the derivative can be written as
Since \( (R_n^{-1})^T = R_n^{-1} \), this equation becomes
Setting the foregoing equation to zero and solving yields
where \( \vec{\hat{\alpha}}_{ML} \) is an ML estimate of \( \vec{\alpha} \).
Unbiased Estimator#
Note that the matrix \( H^T R_n^{-1} H \) must be invertible.
The ML estimate is unbiased since \( \mathbb{E}[\vec{y}] = H \vec{\alpha} \), and
Error Vector#
The error vector \( \vec{\alpha}_e = \vec{\alpha} - \vec{\hat{\alpha}}_{ML} \) is zero mean since the estimate is unbiased. Using Eq. (12.2), the error vector can be reexpressed as
The error covariance matrix \( R_{\vec{\alpha}_e} = \mathbb{E} \{\vec{\alpha}_e \vec{\alpha}_e^T\} \) can now be computed from the preceding equation as
Cramér-Rao bound#
The Cramér-Rao bound is determined for this case by using the elements \( F_{ij} \) from the Fisher information matrix (defined previously) and repeated here for convenience as
Computing the derivative
and taking the expectation yields the matrix
Using the identity
where \( P \) and \( \vec{v} \) are defined before as
\( P \) is an arbitrary \( k \times k \) element matrix
\( \vec{w} \) and \( \vec{v} \) are \( k \)-element real column vectors
Thus, this matrix to be written as
The Cramér-Rao bound is obtained from the elements of \( G = F^{-1} \), i.e.,
Comparing \(R_{\vec{\alpha}_e}\) and \(G\), it can be seen that the lower bound is attained, and thus the ML estimate is a minimum-variance estimate.
Example#
In this example [B2, Ex. 12.2], a simple numerical example is provided to demonstrate the computations involved.
Assume that \( k = 2 \) with \( H \) given by
From
the received measurements are then
Assume further that the noise is zero mean with a covariance matrix given by
implying
ML Estimator:
We have that
Theoretical Derivation
Compute \( H^T R_n^{-1} \)
First, compute the transpose of \( H \):
Now, compute \( H^T R_n^{-1} \):
Compute \( H^T R_n^{-1} H \)
Multiply \( H^T R_n^{-1} \) with \( H \):
Invert \( H^T R_n^{-1} H \)
Compute the inverse of \( H^T R_n^{-1} H \):
Where:
Thus,
Derive the ML Estimator
The ML estimator is given by:
Substituting the computed matrices:
Perform the matrix multiplication:
Thus, the ML estimators for \( \alpha_1 \) and \( \alpha_2 \) are:
Cramér-Rao Bound (CRB)
The CRB provides a lower bound on the variance of unbiased estimators and is given by the diagonal elements of \( (H^T R_n^{-1} H)^{-1} \):
Simulation#
import numpy as np
import matplotlib.pyplot as plt
# Number of simulation runs
num_simulations = 1000
# Define true parameters
alpha_true = np.array([1.0, 2.0]) # Example values for alpha1 and alpha2
# Define H matrix
H = np.array([
[2, 1],
[-2, 1]
])
# Define noise covariance matrix R_n and its inverse R_n_inv
R_n_inv = np.array([
[1, -1],
[-1, 2]
])
# Compute R_n by inverting R_n_inv
R_n = np.linalg.inv(R_n_inv)
# Compute H^T R_n^{-1} H
Ht_Rn_inv = H.T @ R_n_inv
Ht_Rn_H = Ht_Rn_inv @ H
# Compute the inverse of H^T R_n^{-1} H
Ht_Rn_H_inv = np.linalg.inv(Ht_Rn_H)
# Compute the ML estimator matrix
ML_estimator = Ht_Rn_H_inv @ Ht_Rn_inv # This results in a 2x2 matrix
# Verify ML_estimator matches theoretical expressions
# Expected:
# ML_estimator = [[1/4, -1/4],
# [1/2, 1/2]]
# Due to floating point arithmetic, allow for small deviations
expected_ML_estimator = np.array([
[0.25, -0.25],
[0.5, 0.5]
])
assert np.allclose(ML_estimator, expected_ML_estimator), "ML Estimator does not match expected values."
# Initialize arrays to store estimates
alpha_estimates = np.zeros((num_simulations, 2))
# Perform simulations
for i in range(num_simulations):
# Generate noise sample from multivariate normal distribution
noise = np.random.multivariate_normal(mean=np.zeros(2), cov=R_n)
# Generate measurement y
y = H @ alpha_true + noise
# Compute ML estimates
alpha_ml = ML_estimator @ y
# Store estimates
alpha_estimates[i] = alpha_ml
# Compute statistics
alpha_mean = np.mean(alpha_estimates, axis=0)
alpha_std = np.std(alpha_estimates, axis=0)
cramer_rao_bounds = np.diag(Ht_Rn_H_inv) # Extract variances from the inverse matrix
# Display results
print("True Parameters:")
print(f"alpha1 = {alpha_true[0]}, alpha2 = {alpha_true[1]}\n")
print("Estimated Parameters (Mean ± Std Dev):")
print(f"alpha1 = {alpha_mean[0]:.4f} ± {alpha_std[0]:.4f}")
print(f"alpha2 = {alpha_mean[1]:.4f} ± {alpha_std[1]:.4f}\n")
print("Cramér-Rao Bounds:")
print(f"Var(alpha1) >= {cramer_rao_bounds[0]:.4f}")
print(f"Var(alpha2) >= {cramer_rao_bounds[1]:.4f}")
# Visualization
# Scatter plot of estimated vs true parameters
plt.figure(figsize=(14, 6))
plt.subplot(1, 2, 1)
plt.scatter(alpha_estimates[:, 0], alpha_estimates[:, 1], alpha=0.2, label='Estimates', color='blue', edgecolor='none')
plt.plot(alpha_true[0], alpha_true[1], 'ro', label='True Value')
plt.title('Estimated vs True Parameters')
plt.xlabel('alpha1 Estimate')
plt.ylabel('alpha2 Estimate')
plt.legend()
plt.grid(True)
# Histograms of estimates
plt.subplot(1, 2, 2)
plt.hist(alpha_estimates[:, 0], bins=50, alpha=0.7, label='alpha1 Estimates', color='skyblue')
plt.hist(alpha_estimates[:, 1], bins=50, alpha=0.7, label='alpha2 Estimates', color='lightgreen')
plt.axvline(alpha_true[0], color='red', linestyle='dashed', linewidth=2, label='True alpha1')
plt.axvline(alpha_true[1], color='darkgreen', linestyle='dashed', linewidth=2, label='True alpha2')
plt.title('Histogram of Parameter Estimates')
plt.xlabel('Parameter Value')
plt.ylabel('Frequency')
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()
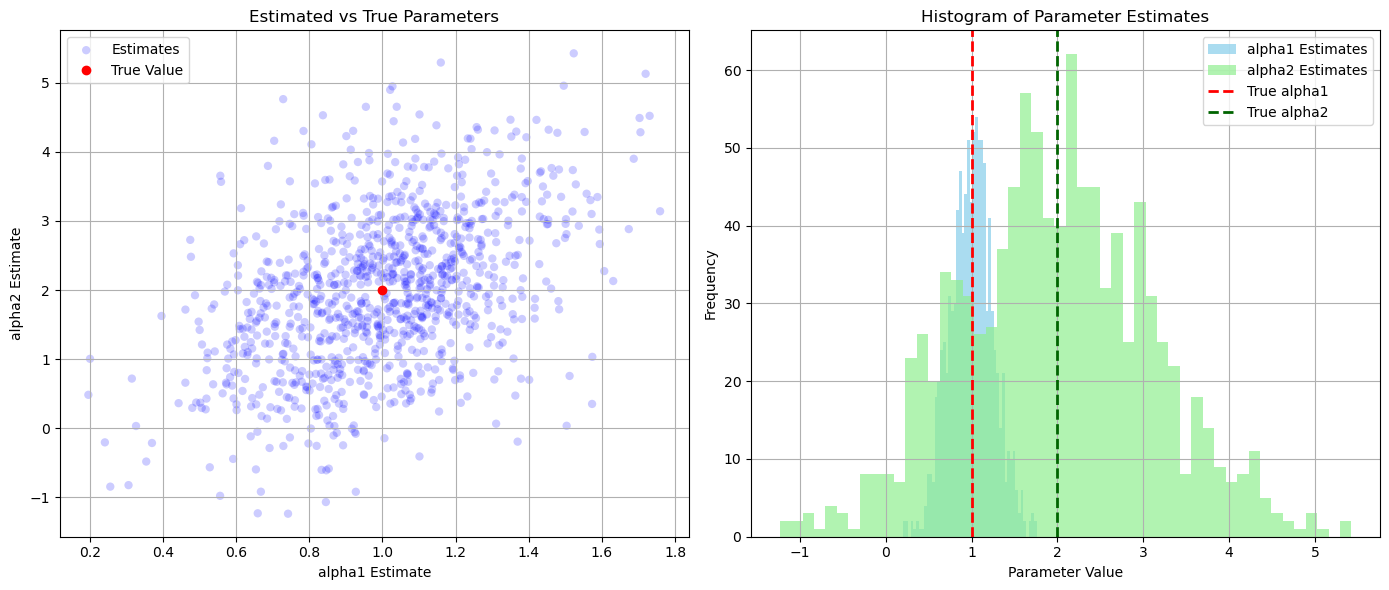
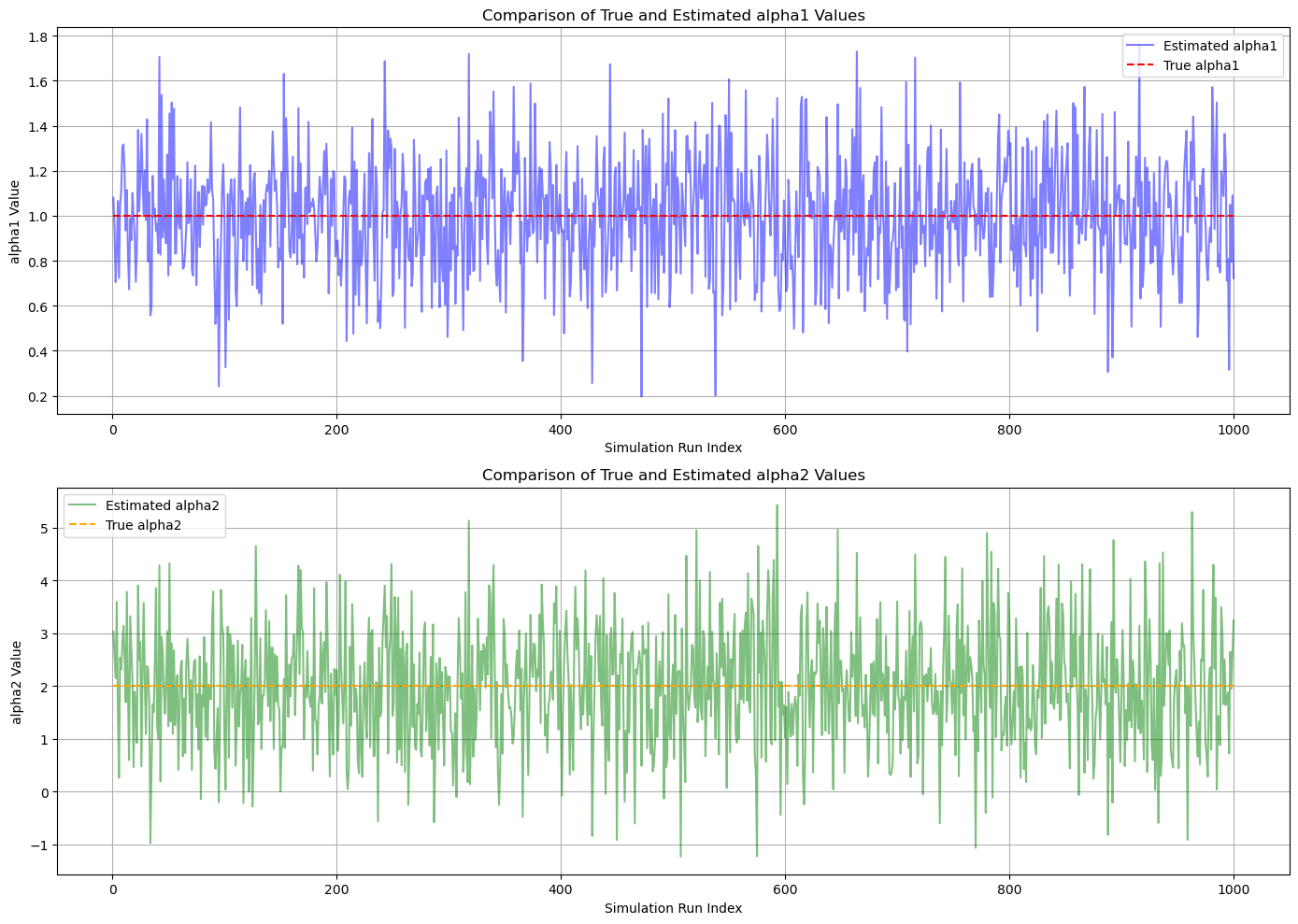
True Parameters:
alpha1 = 1.0, alpha2 = 2.0
Estimated Parameters (Mean ± Std Dev):
alpha1 = 0.9997 ± 0.2532
alpha2 = 1.9733 ± 1.1159
Cramér-Rao Bounds:
Var(alpha1) >= 0.0625
Var(alpha2) >= 1.2500
# Visualization
# Create an array of indices
indices = np.arange(1, num_simulations + 1)
# Plot for alpha1
plt.figure(figsize=(14, 10))
plt.subplot(2, 1, 1)
plt.plot(indices, alpha_estimates[:, 0], label='Estimated alpha1', color='blue', alpha=0.5)
plt.hlines(alpha_true[0], xmin=1, xmax=num_simulations, colors='red', linestyles='dashed', label='True alpha1')
plt.title('Comparison of True and Estimated alpha1 Values')
plt.xlabel('Simulation Run Index')
plt.ylabel('alpha1 Value')
plt.legend()
plt.grid(True)
# Plot for alpha2
plt.subplot(2, 1, 2)
plt.plot(indices, alpha_estimates[:, 1], label='Estimated alpha2', color='green', alpha=0.5)
plt.hlines(alpha_true[1], xmin=1, xmax=num_simulations, colors='orange', linestyles='dashed', label='True alpha2')
plt.title('Comparison of True and Estimated alpha2 Values')
plt.xlabel('Simulation Run Index')
plt.ylabel('alpha2 Value')
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()
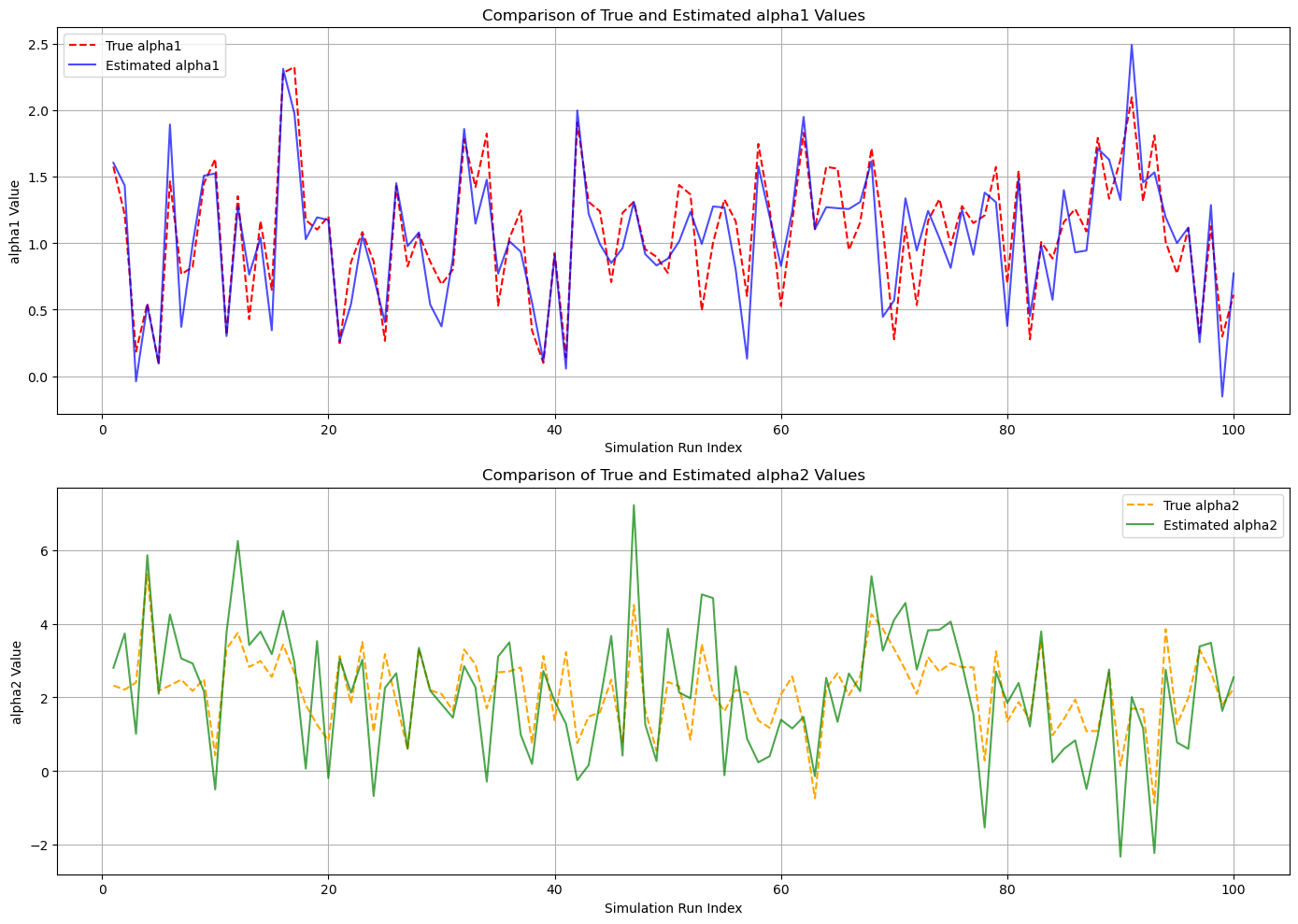
Random Parameters#
import numpy as np
import matplotlib.pyplot as plt
# Number of simulations
num_simulations = 100
# Define true alpha1 and alpha2 distributions
# alpha1: mean=1.0, std=0.5
# alpha2: mean=2.0, std=1.0
mu_a1, sigma_a1 = 1.0, 0.5
mu_a2, sigma_a2 = 2.0, 1.0
# Define H matrix
H = np.array([
[2, 1],
[-2, 1]
])
# Define noise covariance matrix R_n and its inverse R_n_inv
R_n_inv = np.array([
[1, -1],
[-1, 2]
])
# Compute R_n by inverting R_n_inv
R_n = np.linalg.inv(R_n_inv)
# Define the ML estimator matrix directly
ML_estimator = np.array([
[0.25, -0.25],
[0.5, 0.5]
])
# Initialize arrays to store true and estimated parameters
true_alpha1 = np.random.normal(loc=mu_a1, scale=sigma_a1, size=num_simulations)
true_alpha2 = np.random.normal(loc=mu_a2, scale=sigma_a2, size=num_simulations)
alpha_estimates = np.zeros((num_simulations, 2)) # Columns: alpha1_est, alpha2_est
# Perform simulations
for i in range(num_simulations):
# Current true alpha vector
alpha_true = np.array([true_alpha1[i], true_alpha2[i]])
# Generate noise sample from multivariate normal distribution
noise = np.random.multivariate_normal(mean=np.zeros(2), cov=R_n)
# Generate measurement y
y = H @ alpha_true + noise
# Compute ML estimates
alpha_ml = ML_estimator @ y
# Store estimates
alpha_estimates[i] = alpha_ml
# Compute statistics
alpha_est1_mean = np.mean(alpha_estimates[:, 0])
alpha_est1_std = np.std(alpha_estimates[:, 0])
alpha_est2_mean = np.mean(alpha_estimates[:, 1])
alpha_est2_std = np.std(alpha_estimates[:, 1])
# Cramér-Rao Bounds
CRB_alpha1 = 0.0625 # From the diagonal of (H^T Rn^{-1} H)^{-1}
CRB_alpha2 = 1.25 # From the diagonal of (H^T Rn^{-1} H)^{-1}
# Display results
print("True Parameters Distributions:")
print(f"alpha1 ~ N({mu_a1}, {sigma_a1}^2)")
print(f"alpha2 ~ N({mu_a2}, {sigma_a2}^2)\n")
print("Estimated Parameters (Mean ± Std Dev):")
print(f"alpha1_est = {alpha_est1_mean:.4f} ± {alpha_est1_std:.4f}")
print(f"alpha2_est = {alpha_est2_mean:.4f} ± {alpha_est2_std:.4f}\n")
print("Cramér-Rao Bounds:")
print(f"Var(alpha1) >= {CRB_alpha1}")
print(f"Var(alpha2) >= {CRB_alpha2}\n")
# Visualization
# Create an array of indices
indices = np.arange(1, num_simulations + 1)
# Select a subset of indices for clearer plots (e.g., first 1000)
plot_subset = 1000
subset_indices = indices[:plot_subset]
subset_true_a1 = true_alpha1[:plot_subset]
subset_true_a2 = true_alpha2[:plot_subset]
subset_est_a1 = alpha_estimates[:plot_subset, 0]
subset_est_a2 = alpha_estimates[:plot_subset, 1]
# Plot for alpha1
plt.figure(figsize=(14, 10))
plt.subplot(2, 1, 1)
plt.plot(subset_indices, subset_true_a1, label='True alpha1', color='red', linestyle='--')
plt.plot(subset_indices, subset_est_a1, label='Estimated alpha1', color='blue', alpha=0.7)
plt.title('Comparison of True and Estimated alpha1 Values')
plt.xlabel('Simulation Run Index')
plt.ylabel('alpha1 Value')
plt.legend()
plt.grid(True)
# Plot for alpha2
plt.subplot(2, 1, 2)
plt.plot(subset_indices, subset_true_a2, label='True alpha2', color='orange', linestyle='--')
plt.plot(subset_indices, subset_est_a2, label='Estimated alpha2', color='green', alpha=0.7)
plt.title('Comparison of True and Estimated alpha2 Values')
plt.xlabel('Simulation Run Index')
plt.ylabel('alpha2 Value')
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()
True Parameters Distributions:
alpha1 ~ N(1.0, 0.5^2)
alpha2 ~ N(2.0, 1.0^2)
Estimated Parameters (Mean ± Std Dev):
alpha1_est = 1.0373 ± 0.5028
alpha2_est = 2.1288 ± 1.7341
Cramér-Rao Bounds:
Var(alpha1) >= 0.0625
Var(alpha2) >= 1.25