Unknown Phase#
Signal Modelling#
In radio communications and radar systems, estimating the phase of received signals is crucial for tasks like coherent detection, where the exact phase relationship between the transmitted and received signals is used to decode information.
However, accurately estimating the phase can be challenging due to:
Randomness in Phase: The phase of the received signal may vary unpredictably.
Noise: Additive noise can obscure the phase information, making accurate estimation computationally intensive.
Hardware Limitations: High-precision phase estimation requires sophisticated and expensive hardware.
Alternative Detection Schemes
Given the challenges in phase estimation, engineers and researchers seek detection methods that circumvent the need to know the exact phase of the received signal.
These methods ensure reliable communication or detection without the added complexity and cost of phase estimation.
Examples include:
Non-Coherent Detection: Relies on signal envelope or energy rather than phase.
Differential Encoding: Encodes information in phase differences between successive symbols rather than absolute phase.
Signal Representation with Random Phase#
Since we are focusing on a random phase, the received signal
can be re-expressed as
where
\( \alpha \): Amplitude scaling factor.
\( a_i(t - t_0) \): Time-varying amplitude modulation function for hypothesis \( H_i \) with a delay \( t_0 \).
\( 2\pi(f_i + f_d)(t - t_0) \): Carrier frequency \( f_i \) plus Doppler shift \( f_d \), accounting for the delay \( t_0 \).
\( \phi_i(t - t_0) \): Phase modulation component, potentially time-varying.
\( \beta \): Unknown phase offset.
\( z(t) \): Additive noise, typically modeled as complex Gaussian noise.
The re-expression introduces \( \beta_i \) to denote the unknown phase for hypothesis \( H_i \).
This makes it clear that the phase offset is specific to each hypothesis.
Simplifying Signal Modelling
We simplify the signal model to reduce complexity without affecting the generality of the analysis.
We let:
\( f_d = 0 \): to remove the Doppler shift from the equation, focusing solely on the carrier frequency \( f_i \).
\( t_0 = 0 \): to remove the initial delay, simplifying the time variable to start at zero.
Discrete Sampling of the Received Signal
Next, the continuous-time signal \( y(t) \) is sampled at discrete time instances \( t_j \) to obtain \( k \) complex samples \( y_j \).
The \( j \)-th sample under hypothesis \( H_i \) can be written as
where \( i = 0, 1, \quad j = 1, \ldots, k \), and
Time Instances: \( t_j \) for \( j = 1, \ldots, k \) represent the discrete times at which the signal is sampled within the duration \( T \).
Signal Sample: Each sample \( y_j \) under hypothesis \( H_i \) is expressed as a combination of the signal component and noise.
Vector Notation for Samples
To handle \( k \) samples collectively, it’s convenient to use vector notation.
We can write the column vector \( \vec{y} \) as
Note that
\( \vec{y} \): A \( k \times 1 \) column vector containing all received samples \( y_j \) for \( j = 1, \ldots, k \).
\( \vec{u}_i \): A \( k \times 1 \) column vector where each element \( u_{ij} \) corresponds to the known signal component under hypothesis \( H_i \).
\( \vec{z} \): A \( k \times 1 \) column vector representing the noise across all samples.
Conditional Probabilities#
We aim to derive the conditional probability density functions (pdfs) of the received signal vector \( \vec{y} \) under two different hypotheses \( H_0 \) and \( H_1 \).
Our goal is to derive the conditional pdfs \( p_i(\vec{y} | \beta_i) \) for \( i = 0, 1 \).
Assumptions
If the noise is zero mean and white, with a correlation matrix of \( \sigma_z^2 I \), where \( I \) is a \( k \times k \) identity matrix.
Zero Mean: \( \mathbb{E}[\vec{z}] = \vec{0} \).
White Noise: The noise is uncorrelated across different samples.
Correlation Matrix (Covariance Matrix): \( \mathbb{E}[\vec{z} \vec{z}^H] = \sigma_z^2 I \), where \( I \) is the \( k \times k \) identity matrix.
Note that \( \sigma_z^2 = 2 \sigma^2 \), which accounts for the variance in both the real and imaginary parts of the noise.
Under each hypothesis \( H_i \), the received signal vector \( \vec{y} \) is composed of a deterministic signal component \( \alpha \vec{u}_i e^{j \beta_i} \) plus the stochastic noise \( \vec{z} \).
Since \( \vec{z} \) is complex Gaussian with zero mean and covariance \( \sigma_z^2 I \), \( \vec{y} \) conditioned on \( \beta_i \) under hypothesis \( H_i \) is also complex Gaussian with mean \( \alpha \vec{u}_i e^{j \beta_i} \) and covariance \( \sigma_z^2 I \).
Thus, the conditional pdf \( p_i(\vec{y} | \beta_i) \) is given by:
Note:
The factor \( (2\pi \sigma_z^2)^k \) in the denominator, which is commonly used when considering both real and imaginary parts separately.
The factor \( \frac{1}{2} \) is included to account for the fact that \( \sigma_z^2 \) represents the variance per complex dimension (both real and imaginary parts).
The squared norm \( \|\vec{y} - \alpha \vec{u}_i e^{j \beta_i}\|^2 \) can be expanded as:
Alternatively, the conditional density functions can be expressed as
and
Simplifying
Breaking the norm down:
where
\( \vec{y}^H \vec{y} = \sum_{j=1}^k |y_j|^2 \): Sum of squared magnitudes of the received samples.
\( \vec{y}^H \vec{u}_i = \sum_{j=1}^k y_j^* u_{ij} \): Inner product between \( \vec{y} \) and \( \vec{u}_i \).
\( \vec{u}_i^H \vec{u}_i = \sum_{j=1}^k |u_{ij}|^2 \): Sum of squared magnitudes of the known signal components.
Substituting the expanded norm back into the conditional pdf:
Simplifying the Exponential Term
We can rearrange the terms inside the exponential to separate the components that depend on \( \beta_i \) from those that don’t:
Notice that the first bracketed term is real and independent of \( \beta_i \), while the second bracketed term involves \( \beta_i \).
Expressing in Terms of Magnitude and Phase
We denote:
where:
\( R_i = \left| \sum_{j=1}^k y_j u_{ij}^* \right| \): Magnitude of the inner product.
\( \xi_i = \angle\left( \sum_{j=1}^k y_j u_{ij}^* \right) \): Phase angle of the inner product.
Then, its complex conjugate is:
Substituting these into the exponential term:
Certainly. Here is the simplification in one equation:
Combining all the simplified terms, the conditional pdf becomes:
where \( R_i = \left| \sum_{j=1}^k y_j u_{ij}^* \right| \) is the magnitude.
Specifically:
where:
\( u_{ij} \) is the \( j \)-th component of the known signal vector \( \vec{u}_i \) under hypothesis \( H_i \).
\( \xi_i = \arg\left( \sum_{j=1}^k y_j u_{ij}^* \right) \).
Uniform Distribution for \( \beta_i \)#
When designing detection schemes, any prior information about the unknown parameters can significantly influence the approach. In the absence of specific information about the phase \( \beta_i \), we must rely on reasonable and justifiable assumptions to proceed.
One fundamental principle in statistics and information theory is the Maximum Entropy Principle, which states that, subject to known constraints, the probability distribution which best represents the current state of knowledge is the one with the largest entropy.
Without any additional information about \( \beta_i \), the uniform distribution maximizes entropy, implying maximum uncertainty.
The phase \( \beta_i \) inherently has a circular nature, meaning that \( \beta_i \) and \( \beta_i + 2\pi \) represent the same physical state.
Assuming a uniform distribution simplifies mathematical derivations and computations in detection schemes.
Given the reasons above, we define the probability density function (pdf) of the unknown phase \( \beta_i \) as:
Note that:
\( \frac{1}{2\pi} \): Constant value ensuring that the total probability over the interval \( (0, 2\pi) \) is 1.
\[ \int_{0}^{2\pi} p(\beta_i) \, d\beta_i = \int_{0}^{2\pi} \frac{1}{2\pi} \, d\beta_i = 1 \]\( 0 \le \beta_i < 2\pi \): Specifies the domain of \( \beta_i \), acknowledging the periodicity of the phase.
Expressing in Terms of Bessel function#
Express the Unconditional PDF as an Integral Over \( \beta_i \)
Starting with the definition of the unconditional pdf:
Given that \( p(\beta_i) = \frac{1}{2\pi} \), we substitute:
Insert the expression for \( p_i(\vec{y} | \beta_i) \):
Observe that several terms inside the integral do not depend on \( \beta_i \), which can be factored out:
Recognize the Integral as a Modified Bessel Function
The integral in the expression is of the form:
where:
\( x = \frac{\alpha}{\sigma_z^2} \left| \sum_{j=1}^k y_j u_{ij}^* \right| \)
\( \theta = \beta_i - \xi_i \)
Thus, substituting \( x \) and recognizing the integral:
Plug the result of the integral back into the expression for \( p_i(\vec{y}) \):
Simplify the Expression
Cancel out the \( 2\pi \) terms:
Thus:
Hence, the unconditional pdf \( p_i(\vec{y}) \) under hypothesis \( H_i \) is:
where \( I_0 \left( \frac{\alpha}{\sigma_z^2} \left| \sum_{j=1}^k y_j u_{ij}^* \right| \right) \) is the modified Bessel function of the first kind of order zero.
The Modified Bessel Function \( I_0(x) \)#
The modified Bessel function of the first kind of order zero, \( I_0(x) \), is defined as:
where \( \theta \) is a dummy variable representing the angle.
Properties Relevant to Detection
Positive Definiteness: \( I_0(x) \) is always positive for real \( x \), which ensures the unconditional pdf remains valid.
Monotonicity: \( I_0(x) \) is monotonically increasing for \( x \geq 0 \), meaning higher inner product magnitudes lead to higher likelihoods.
Asymptotic Behavior:
For small \( x \), \( I_0(x) \approx 1 + \frac{x^2}{4} \).
For large \( x \), \( I_0(x) \approx \frac{e^x}{\sqrt{2\pi x}} \).
Log-Likelihood Ratio (LLR)#
Note that we use the unconditional PDF \(p_i(\vec{y})\), instead of the conditional PDF (likelihood) \(p_i(\vec{y} | \beta_i)\), because we already assume that \(\beta_i\) is uniform.
The Likelihood Ratio (LR) is defined as:
The Log-Likelihood Ratio (LLR) is thus:
Using the expressions for \( p_1(\vec{y}) \) and \( p_0(\vec{y}) \), we substitute them into the LLR:
Simplifying the Logarithms
The logarithm of a product is the sum of logarithms, and constants cancel out. Applying this property:
Thus, we have
Decision Variable \( U_i \)#
We define the decision variable as
Thus, the LLR becomes:
Decision Rule Based on LLR#
We have
Simplification Under Equal Energy#
When both hypotheses \( H_0 \) and \( H_1 \) involve signals of equal energy, certain terms in the LLR become constant and thus irrelevant for the decision-making process.
Equal Energy Assumption
We have
The energy terms \( \frac{\alpha^2}{2\sigma_z^2} \sum |u_{ij}|^2 \) for \( i = 0, 1 \) cancel out or remain constant relative to each other, thus not affecting the relative likelihoods.
Under the equal energy assumption, the decision variables \( U_i \) simplify to:
Additionally, the scalar factor \( \frac{\alpha^2}{\sigma_z^2} \) does not affect the decision boundary since it is a constant multiplier for both hypotheses. Therefore, it can be safely ignored when comparing \( U_1 \) and \( U_0 \).
Under equal energy and ignoring scalar constants, the decision variables simplify further to:
So, one can observe that:
The LLR depends primarily on the magnitude of the inner product between the received signal \( \vec{y} \) and each known signal \( \vec{u}_i \).
The phase information, encapsulated within the Bessel function \( I_0 \), is accounted for by the uniform distribution assumption and the nature of \( I_0 \).
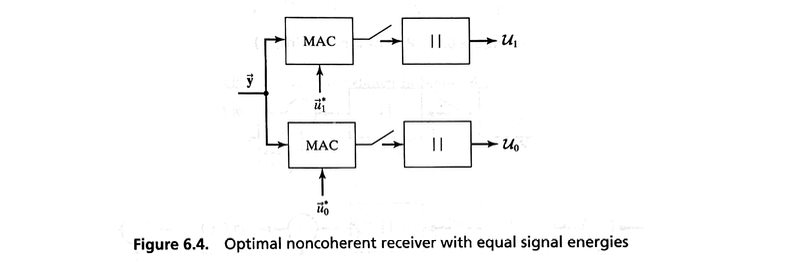
Noncoherent Receiver Structure#
We can now draw a general functional block diagram of the optimal receiver structure as shown in Figure 6.3.
Because of the lack of phase knowledge, this receiver is referred to as noncoherent.

The receiver first correlates the received signal \( \vec{y} \) with each of the locally generated signals \( \vec{u}_0^* \) and \( \vec{u}_1^* \).
The magnitude of each correlation is determined and scaled by the term \( \alpha / \sigma_z^2 \).
The resultant scaled magnitude is then processed by a nonlinear transformation, corresponding to \( \ln I_0(\cdot) \).
Finally a bias term is subtracted from each branch.
The bias term is
If both signals have equal energy, then the two bias terms are equal and can be eliminated from the receiver.
Furthermore, the nonlinear transformation is monotonic, so in the case of equal-energy signals, this nonlinear device need not be implemented.
These simplifications result in the noncoherent receiver structure of Figure 6.4.
Nonlinearity#
In the general case, represented by Figure 6.3, we must include the nonlinearity.
A number of points can be made about it:
If an optimal noncoherent receiver is built using digital circuitry, then the \( \ln I_0(\cdot) \) function can be approximated by a table look-up.
If an optimal noncoherent receiver is built using analog circuitry, whose functional block diagram is shown in Figure 6.6, the \( \ln I_0(\cdot) \) function can be approximated using a circuit containing resistors and diodes.
If \( x \) is large, it can be shown that \( \ln I_0(x) \approx x \); thus, a “high-SNR” receiver can be built using a linear approximation.
If \( x \) is small, \( \ln I_0(x) \approx x^2 / 4 \), thereby allowing a “low-SNR” receiver to be built using a square-law device.
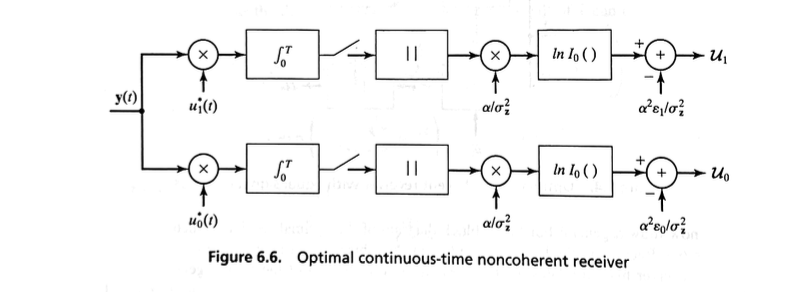
Evaluating the performance of noncoherent receivers is, in general, exceedingly difficult.
Indeed, if the \( \ln I_0(\cdot) \) function is included in the receiver, then no known analytical techniques have been developed to determine the performance.
If, however, the two hypotheses represent signals of equal energy, the simplified receiver of Figure 6.4 is appropriate and an evaluation of its error-rate performance is possible.
Error-Rate Performance#
Assuming that \( \vec{u}_0 \) is sent.
The probability of error \( P_E \) is the probability that the decision rule incorrectly selects \( H_1 \) when \( H_0 \) is true:
For equally likely transmission of \( \vec{u}_0 \) and \( \vec{u}_1 \), \(P_E\) is
Rician \(U_0\)#
The received signal, with \( \vec{u}_0 \) sent, is
Examining the lower branch of the receiver shown in Figure 6.4 reveals that
where
Note that \( \mathcal{N}_0 \) is a complex Gaussian random variable with \( E\{\mathcal{N}_0\} = 0 \) and \( \text{Var} \{\mathcal{N}_0\} = 2\sigma_z^2 \mathcal{E} \), since
Therefore, \( U_0 \) is Rician with pdf
where \( \sigma_v^2 = \sigma_z^2 \mathcal{E} \).
Rician Distribution of \( U_0 \)#
A particular signal \( \vec{u}_0 \) is transmitted.
The received signal vector \( \vec{y} \) is:
The decision variable \( U_0 \):
Given \( \vec{y} = \alpha \vec{u}_0 e^{j \beta_0} + \vec{z} \), we substitute into the expression for \( U_0 \):
Simplifying the Expression
Notice that \( u_{0j} e^{j \beta_0} u_{0j}^* \) simplifies as follows:
Thus, the expression for \( U_0 \) becomes:
Energy \( \mathcal{E} \)
Define the energy \( \mathcal{E} \) of the signal vector \( \vec{u}_0 \) as:
Therefore, the expression simplifies to:
where:
Distribution of \( \mathcal{N}_0 \)#
We have
Mean of \( \mathcal{N}_0 \)
Since \( \vec{z} \) is zero-mean noise, and \( e^{-j \beta_0} \) is a deterministic phase rotation (given \( \beta_0 \)), we have:
Variance of \( \mathcal{N}_0 \)
To compute \( \text{Var}\left\{ \mathcal{N}_0 \right\} \), we consider the covariance between different noise components.
Given that \( \vec{z} \) is white noise, noise components are uncorrelated for \( j \neq \ell \):
Therefore:
Given the uncorrelated noise:
(Recall \( \mathcal{E} = \sum_{j=1}^k |u_{0j}|^2 \))
Note: The factor of 2 appears in the user’s expression because in complex Gaussian noise, variance is often split between real and imaginary parts.
Here, since \( \mathcal{N}_0 \) is complex, the total variance includes both components:
This accounts for the variance in both the real and imaginary parts of \( \mathcal{N}_0 \).
Distribution of \( \mathcal{N}_0 \):
Given that \( \mathcal{N}_0 \) is a linear combination of Gaussian random variables, it itself is a complex Gaussian random variable with:
Rician Distribution#
A Rician distribution describes the magnitude of a complex Gaussian random variable with a non-zero mean.
It is characterized by two parameters:
K-factor (\( K \)): Ratio of the power in the direct (deterministic) component to the power in the scattered (random) component.
Scale Parameter (\( \sigma^2 \)): Variance of the underlying Gaussian noise.
PDF of Rician Distribution
The probability density function of a Rician distributed random variable \( r \) is:
where:
\( s \): Amplitude of the deterministic component.
\( I_0(\cdot) \): Modified Bessel function of the first kind of order zero.
Rician PDF for \( U_0 \)#
In our context, \( U_0 \) is the magnitude of a complex random variable that combines a deterministic component \( 2 \alpha \mathcal{E} \) and a Gaussian noise component \( \mathcal{N}_0 \).
Thus, \( U_0 \) follows a Rician distribution.
Specifically
Here:
Deterministic Component (\( s \)): \( 2 \alpha \mathcal{E} \)
Random Component (\( \mathcal{N}_0 \)): Complex Gaussian noise with variance \( 2 \sigma_z^2 \mathcal{E} \)
Mapping to Rician Parameters
Comparing with the standard Rician distribution:
where:
\( s \): Deterministic signal
\( n \): Complex Gaussian noise with variance \( 2 \sigma_z^2 \mathcal{E} \)
Thus:
Deterministic Amplitude (\( s \)): \( 2 \alpha \mathcal{E} \)
Scale Parameter (\( \sigma_v^2 \)): \( \sigma_v^2 = \sigma_z^2 \mathcal{E} \)
(Note: The variance in the Rician pdf is often expressed per dimension; hence, \( \sigma_v^2 = \sigma_z^2 \mathcal{E} \) aligns with standard notation.)
Substituting the parameters into the Rician pdf formula:
Substituting \( s = 2 \alpha \mathcal{E} \) and \( \sigma_v^2 = \sigma_z^2 \mathcal{E} \):
Simplifying:
We have the final PDF is
where \( \sigma_v^2 = \sigma_z^2 \mathcal{E} \).
Definition of \( U_1 \):#
We have
Given \( \vec{y} = \alpha \vec{u}_0 e^{j \beta_0} + \vec{z} \), substitute into the expression for \( U_1 \):
Recall that, we define the energy \( \mathcal{E} \) of the signal vector \( \vec{u}_0 \) as:
Cross-Correlation Coefficient \( \rho \)
Define the cross-correlation coefficient \( \rho \) between \( \vec{u}_0 \) and \( \vec{u}_1 \) as:
This definition normalizes the cross-correlation by the energy \( \mathcal{E} \) of \( \vec{u}_0 \), and the factor \( \frac{1}{2} \) is introduced for scaling purposes.
Next, we express \( U_1 \) in terms of \( \rho \) and \( \mathcal{N}_1 \):
Here, the step from \( \alpha \sum u_{0j} e^{j \beta_0} u_{1j}^* \) to \( \alpha \cdot 2\mathcal{E} \rho e^{j \beta_0} \) utilizes the definition of \( \rho \).
Thus, the expression for \( U_1 \) simplifies to:
where:
Finally, we have:
with:
Distribution of \( \mathcal{N}_1 \)#
We have
Mean of \( \mathcal{N}_1 \):
Since \( \vec{z} \) is zero-mean noise, and \( e^{-j \beta_0} \) is a deterministic phase rotation, the mean of \( \mathcal{N}_1 \) is:
Variance of \( \mathcal{N}_1 \)
To compute the variance, we consider the covariance of \( \mathcal{N}_1 \):
Given that the noise \( z_j \) and \( z_\ell \) are uncorrelated for \( j \neq \ell \):
Therefore:
where \( \mathcal{E}_1 = \sum_{j=1}^k |u_{1j}|^2 \).
Not that we consider the variance per dimension for complex Gaussian variables. For a complex Gaussian variable \( z = z_{\text{real}} + j z_{\text{imag}} \), each of \( z_{\text{real}} \) and \( z_{\text{imag}} \) has variance \( \frac{\sigma_z^2}{2} \) to ensure that \( \text{Var}\{z\} = \sigma_z^2 \).
Therefore, the final expression, accounting for both real and imaginary parts, is:
Distribution of \( \mathcal{N}_1 \):
Since \( \mathcal{N}_1 \) is a linear combination of complex Gaussian variables, it itself is a complex Gaussian random variable:
Rician Distribution for \( U_1 \)#
We have
where:
Deterministic Component: \( 2\alpha \mathcal{E} \rho \)
Random Component: \( \mathcal{N}_1 \sim \mathcal{CN}\left(0, 2\sigma_z^2 \mathcal{E}\right) \)
Comparing to the standard Rician formulation:
Deterministic Component (\( s \)): \( 2\alpha \mathcal{E} \rho \)
Since \( \rho \) is a complex scalar, \( |s| = 2\alpha \mathcal{E} |\rho| \).
Scale Parameter (\( \sigma_v^2 \)): \( \sigma_v^2 = \sigma_z^2 \mathcal{E} \)
Thus, \( U_1 \) follows a Rician distribution with:
Noncentrality Parameter: \( s = 2\alpha \mathcal{E} |\rho| \)
Scale Parameter: \( \sigma_v^2 = \sigma_z^2 \mathcal{E} \)
Deriving the PDF of \( U_1 \)#
Given:
Noncentrality Parameter (\( s \)): \( s = 2\alpha \mathcal{E} |\rho| \)
Scale Parameter (\( \sigma_v^2 \)): \( \sigma_v^2 = \sigma_z^2 \mathcal{E} \)
Substituting these into the Rician PDF formula:
Thus, we have
where \( \sigma_v^2 = \sigma_z^2 \mathcal{E} \).
Average Error Rate#
Analytical Approach#
While the exact joint pdf \( p(U_0, U_1) \) is complex due to the dependence, an analytical expression for \( P_E \) can be expressed as:
This double integral accounts for all instances where \( U_1 \) exceeds \( U_0 \).
In some cases, analytical derivation of the joint pdf may be complex.
However, knowledge of the individual pdfs \( p(U_0) \) and \( p(U_1) \), along with their dependence structure, allows for approximate or simulation-based methods to estimate \( P_E \).
Approximation Method#
The average error rate is then obtained as follows.
This error rate corresponds to the general case of correlated Rice variates where one Rician variable exceeds another.
By a linear transformation, the problem can be converted to the case where one Rician variable exceeds another and the two variables are independent.
The average error rate is expressed as
where \( Q(x, w) \) is Marcum’s \(Q\) function, with
and
It can easily be shown that the error rate, given that \( \vec{u}_1 \) is sent, is the same as \(P_E\) above.
Thus, this expression also corresponds to the average error rate.
Special Case: Orthogonal Signaling \(\rho = 0\)#
In general, it is advantageous to choose signals for which \( \rho = 0 \), if it is possible to do so. In this case, \( x = 0 \),
and the average error rate is
From the definition of Marcum’s \(Q\) function, we have
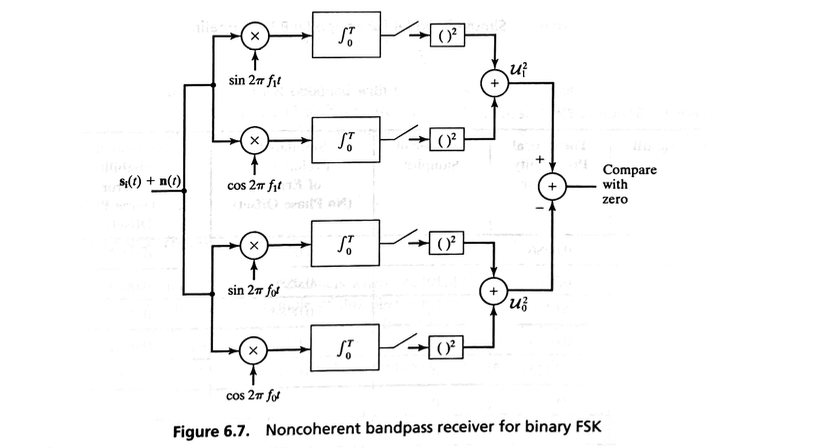
A common signaling scheme requiring the use of noncoherent receivers is frequency-shift keying (FSK).
In this case, each of the two complex baseband equivalent signals is modeled as
where \( \beta \) is a random variable uniformly distributed on the interval \( (0, 2\pi) \).
It is easy to show that the correlation between them has a magnitude
where \( \Delta f = |f_1 - f_0| \) is the frequency separation between the signals.
Clearly, if \( \Delta f \) is a multiple of \( 1/T \), then \( |\rho| = 0 \) and we have orthogonal signaling.
Although Figure 6.4 shows a functional block diagram of an equal-energy noncoherent receiver, it is instructive to compare this structure to the bandpass noncoherent receiver for FSK.
The structure shown in Figure 6.7 can be obtained by rewriting:
for \( i = 0, 1\)
Simulation#
import numpy as np
from scipy.special import i0
from marcumq import marcumq
import matplotlib.pyplot as plt
# Set random seed for reproducibility
np.random.seed(13)
# Simulation Parameters
# System Parameters
alpha = 1.0 # Scaling factor
E = 1 # Energy
sigma_z_squared = 1.0 # Noise variance
rho = 0.1 # Correlation coefficient (0 <= |rho| <= 1)
# Simulation Parameters
num_simulations = int(1e6) # Number of Monte Carlo simulations
# Derived Parameters
sigma_v_squared = sigma_z_squared * E
sigma_v = np.sqrt(sigma_v_squared)
# Ensure rho is within valid range
if np.abs(rho) > 1:
raise ValueError("Correlation coefficient rho must satisfy |rho| <= 1.")
# === Monte Carlo Simulation ===
# Generate complex Gaussian noise N0 and N1
# Each component (real and imaginary) has variance sigma_z_squared * E
N0_real = np.random.normal(0, np.sqrt(sigma_z_squared * E), num_simulations)
N0_imag = np.random.normal(0, np.sqrt(sigma_z_squared * E), num_simulations)
N0 = N0_real + 1j * N0_imag
N1_real = np.random.normal(0, np.sqrt(sigma_z_squared * E), num_simulations)
N1_imag = np.random.normal(0, np.sqrt(sigma_z_squared * E), num_simulations)
N1 = N1_real + 1j * N1_imag
# Compute U0 and U1
U0 = np.abs(2 * alpha * E + N0)
U1 = np.abs(2 * alpha * E * rho + N1)
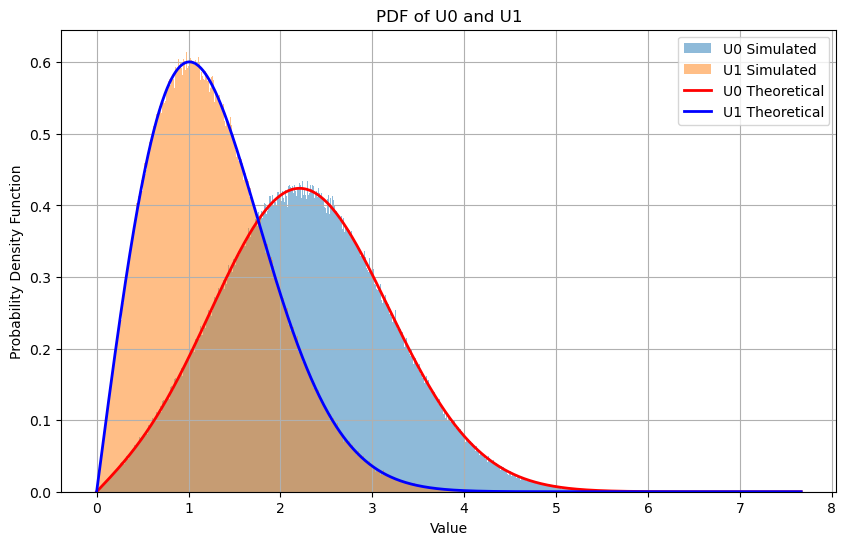
PDFs#
# Define range for x-axis based on simulated data
x_min = 0
x_max = max(U0.max(), U1.max()) * 1.1 # Extend range slightly for better visualization
x_values = np.linspace(x_min, x_max, 1000)
# Plot empirical PDFs using histograms
# max_value = max(U0.max(), U1.max())
bins = np.linspace(0, x_max, 1000)
plt.figure(figsize=(10, 6))
plt.hist(U0, bins=bins, density=True, alpha=0.5, label='U0 Simulated')
plt.hist(U1, bins=bins, density=True, alpha=0.5, label='U1 Simulated')
# To compute theoretical PDFs over x_values using manual implementation
def rician_pdf(r, s, sigma_v2):
return (r / sigma_v2) * np.exp(-(r**2 + s**2) / (2 * sigma_v2)) * i0((r * s) / sigma_v2)
# Compute s parameters for U0 and U1
s_U0 = np.abs(2 * alpha * E) # Signal amplitude for U0
s_U1 = np.abs(2 * alpha * E * rho) # Signal amplitude for U1
sigma_v2 = sigma_v_squared # Variance of the noise
# Compute theoretical PDFs over x_values
theoretical_p_U0 = rician_pdf(x_values, s_U0, sigma_v2)
theoretical_p_U1 = rician_pdf(x_values, s_U1, sigma_v2)
# Plot theoretical PDFs
plt.plot(x_values, theoretical_p_U0, 'r-', lw=2, label='U0 Theoretical')
plt.plot(x_values, theoretical_p_U1, 'b-', lw=2, label='U1 Theoretical')
plt.xlabel('Value')
plt.ylabel('Probability Density Function')
plt.title('PDF of U0 and U1')
plt.legend()
plt.grid(True)
plt.show()
Empirical vs. Theoretical \(P_E\)#
# Estimate empirical P_E
P_E_empirical = np.mean(U1 > U0)
# Compute Theoretical P_E using the closed-form expression
# Define x and w as per the closed-form expression
sqrt_term = np.sqrt(1 - np.abs(rho)**2)
x = np.sqrt((alpha**2 * E) / sigma_z_squared * (1 - sqrt_term))
w = np.sqrt((alpha**2 * E) / sigma_z_squared * (1 + sqrt_term))
# Compute the Marcum Q function Q_1(x, w)
# Note: scipy.special.marcumq(m, a, b) computes Q_m(a, b)
Q_1_xw = marcumq(1, x, w)
# Compute the modified Bessel function I0(xw)
I0_xw = i0(x * w)
# Compute the exponential term
exp_term = np.exp(-(x**2 + w**2) / 2)
# Compute theoretical P_E
P_E_theoretical = Q_1_xw - 0.5 * exp_term * I0_xw
# Display results
print(f"Theoretical P_E: {P_E_theoretical:.6f}")
print(f"Empirical P_E: {P_E_empirical:.6f}")
Theoretical P_E: 0.185324
Empirical P_E: 0.187643
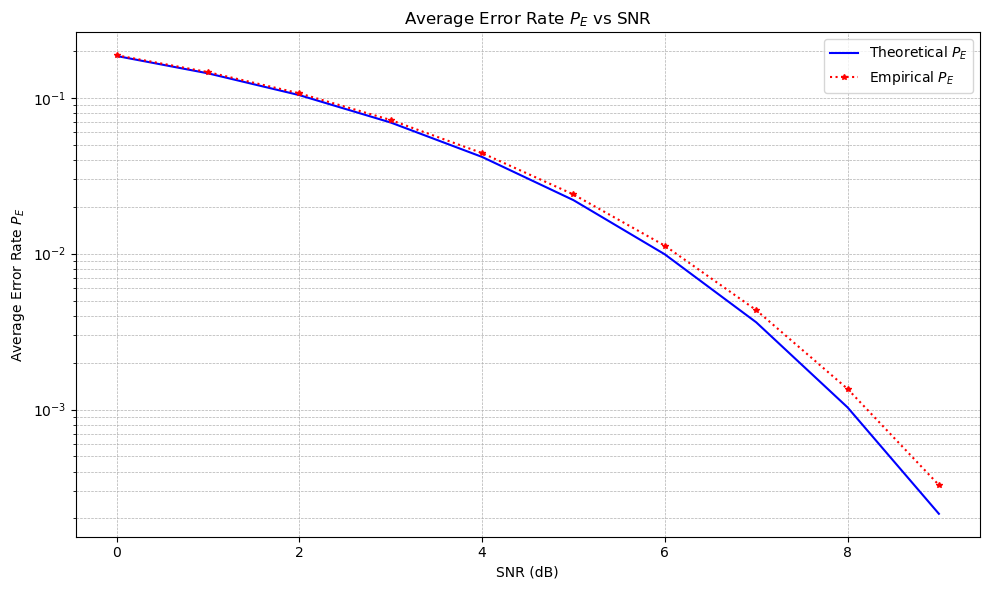
\(P_E\) as A Function of SNR#
# Set random seed for reproducibility
np.random.seed(13)
# System Parameters
alpha = 1.0 # Scaling factor
rho = 0.1 # Correlation coefficient (0 <= |rho| <= 1)
# Noise variance
sigma_z_squared = 1.0 # Noise variance (fixed)
# Simulation Parameters
num_simulations = int(1e7) # Number of Monte Carlo simulations per SNR point
# SNR Parameters
SNR_dB_range = np.arange(0, 10, 1) # SNR in dB
# Initialize arrays to store theoretical and empirical P_E
P_E_theoretical_array = []
P_E_empirical_array = []
# Loop over each SNR value
for SNR_dB in SNR_dB_range:
# Convert SNR from dB to linear scale
SNR_linear = 10**(SNR_dB / 10)
# Compute energy E based on SNR: SNR = E / sigma_z_squared => E = SNR * sigma_z_squared
E = SNR_linear * sigma_z_squared
# Theoretical P_E Calculation
# Compute sqrt_term = sqrt(1 - |rho|^2)
sqrt_term = np.sqrt(1 - np.abs(rho)**2)
# Compute x and w as per the closed-form expression
x = np.sqrt((alpha**2 * E) / sigma_z_squared * (1 - sqrt_term))
w = np.sqrt((alpha**2 * E) / sigma_z_squared * (1 + sqrt_term))
# Compute the Marcum Q function
Q_1_xw = marcumq(1, x, w)
# Compute the modified Bessel function I0(xw)
I0_xw = i0(x * w)
# Compute the exponential term
exp_term = np.exp(-(x**2 + w**2) / 2)
# Compute theoretical P_E
P_E_theoretical = Q_1_xw - 0.5 * exp_term * I0_xw
P_E_theoretical_array.append(P_E_theoretical)
# Monte Carlo Simulation
# Generate complex Gaussian noise N0 and N1
# Each component (real and imaginary) has variance sigma_z_squared * E
N0_real = np.random.normal(0, np.sqrt(sigma_z_squared * E), num_simulations)
N0_imag = np.random.normal(0, np.sqrt(sigma_z_squared * E), num_simulations)
N0 = N0_real + 1j * N0_imag
N1_real = np.random.normal(0, np.sqrt(sigma_z_squared * E), num_simulations)
N1_imag = np.random.normal(0, np.sqrt(sigma_z_squared * E), num_simulations)
N1 = N1_real + 1j * N1_imag
# Compute U0 and U1
U0 = np.abs(2 * alpha * E + N0)
U1 = np.abs(2 * alpha * E * rho + N1)
# Estimate empirical P_E
P_E_empirical = np.mean(U1 > U0)
P_E_empirical_array.append(P_E_empirical)
# === Optional: Print Progress ===
print(f"SNR: {SNR_dB} dB | Theoretical P_E: {P_E_theoretical:.6f} | Empirical P_E: {P_E_empirical:.6f}")
SNR: 0 dB | Theoretical P_E: 0.185324 | Empirical P_E: 0.187374
SNR: 1 dB | Theoretical P_E: 0.143442 | Empirical P_E: 0.146042
SNR: 2 dB | Theoretical P_E: 0.103948 | Empirical P_E: 0.106767
SNR: 3 dB | Theoretical P_E: 0.069352 | Empirical P_E: 0.071942
SNR: 4 dB | Theoretical P_E: 0.041716 | Empirical P_E: 0.044155
SNR: 5 dB | Theoretical P_E: 0.022038 | Empirical P_E: 0.023970
SNR: 6 dB | Theoretical P_E: 0.009897 | Empirical P_E: 0.011247
SNR: 7 dB | Theoretical P_E: 0.003628 | Empirical P_E: 0.004343
SNR: 8 dB | Theoretical P_E: 0.001033 | Empirical P_E: 0.001357
SNR: 9 dB | Theoretical P_E: 0.000214 | Empirical P_E: 0.000328
# Ensure all entries are valid numbers by filtering out None or invalid entries
P_E_theoretical_array = np.array([val for val in P_E_theoretical_array if isinstance(val, (int, float))])
P_E_empirical_array = np.array([val for val in P_E_empirical_array if isinstance(val, (int, float))])
# Plot the theoretical and empirical P_E vs SNR
plt.figure(figsize=(10, 6))
plt.semilogy(SNR_dB_range, P_E_theoretical_array, 'b-', label='Theoretical $P_E$')
plt.semilogy(SNR_dB_range, P_E_empirical_array, 'r*:', markersize=4, label='Empirical $P_E$')
plt.title('Average Error Rate $P_E$ vs SNR')
plt.xlabel('SNR (dB)')
plt.ylabel('Average Error Rate $P_E$')
plt.grid(True, which='both', linestyle='--', linewidth=0.5)
plt.legend()
plt.tight_layout()
plt.show()